DivScore: Zero-Shot Detection of LLM-Generated Text in Specialized Domains DivScore:在专业领域中零样本检测大模型生成文本



Abstract摘要
Detecting LLM-generated text in specialized and high-stakes domains like medicine and law is crucial for combating misinformation and ensuring authenticity. However, current zero-shot detectors, while effective on general text, often fail when applied to specialized content due to domain shift. To address this, we propose DivScore, a zero-shot detection framework using normalized entropy-based scoring and domain knowledge distillation to robustly identify LLM-generated text in specialized domains. DivScore consistently outperforms state-of-the-art detectors, with 14.4% higher AUROC and 64.0% higher TPR at 0.1% FPR threshold.
在医学和法律等专业高风险领域检测大语言模型生成的文本对于打击错误信息和确保真实性至关重要。然而,现有的零样本检测器虽然在通用场景表现良好,但在面对专业领域内容时常因领域迁移带来的分布偏移而失效。为此,我们提出 DivScore,一个结合归一化熵评分与领域知识蒸馏的零样本检测框架,能够稳健识别专业领域中的大模型生成文本。DivScore 在多个基准上均显著领先现有方法,AUROC 提升 14.4%,在 0.1% FPR 阈值下召回率提升 64.0%。
Full Poster完整海报

Click image to view in full size 点击图片查看大图
Method Overview方法概览
DivScore addresses the challenge of detecting LLM-generated text in specialized domains through a novel two-stage approach:
- Domain Knowledge Distillation: We fine-tune a general-purpose LLM (teacher model) on domain-specific texts using knowledge distillation, creating a domain-adapted student model M*.
- Normalized Entropy Scoring: For a given text, we compute the KL divergence between the probability distributions of the general model M and the domain-adapted model M*. This divergence, normalized by text entropy, serves as a detection score.
The key insight is that human-written text shows consistent entropy patterns across both models, while LLM-generated text exhibits significant divergence when evaluated by domain-adapted models.
DivScore 通过两阶段方法解决专业领域中大模型生成文本的检测难题:
- 领域知识蒸馏:我们使用领域特定文本对通用 LLM(教师模型)进行知识蒸馏微调,创建领域适配的学生模型 M*。
- 归一化熵评分:对于给定文本,计算通用模型 M 与领域适配模型 M* 输出概率分布的 KL 散度。该散度经文本熵归一化后作为检测分数。
核心洞察在于:人类撰写的文本在两个模型下表现出一致的熵模式,而大模型生成的文本在领域适配模型评估时会呈现显著偏差。
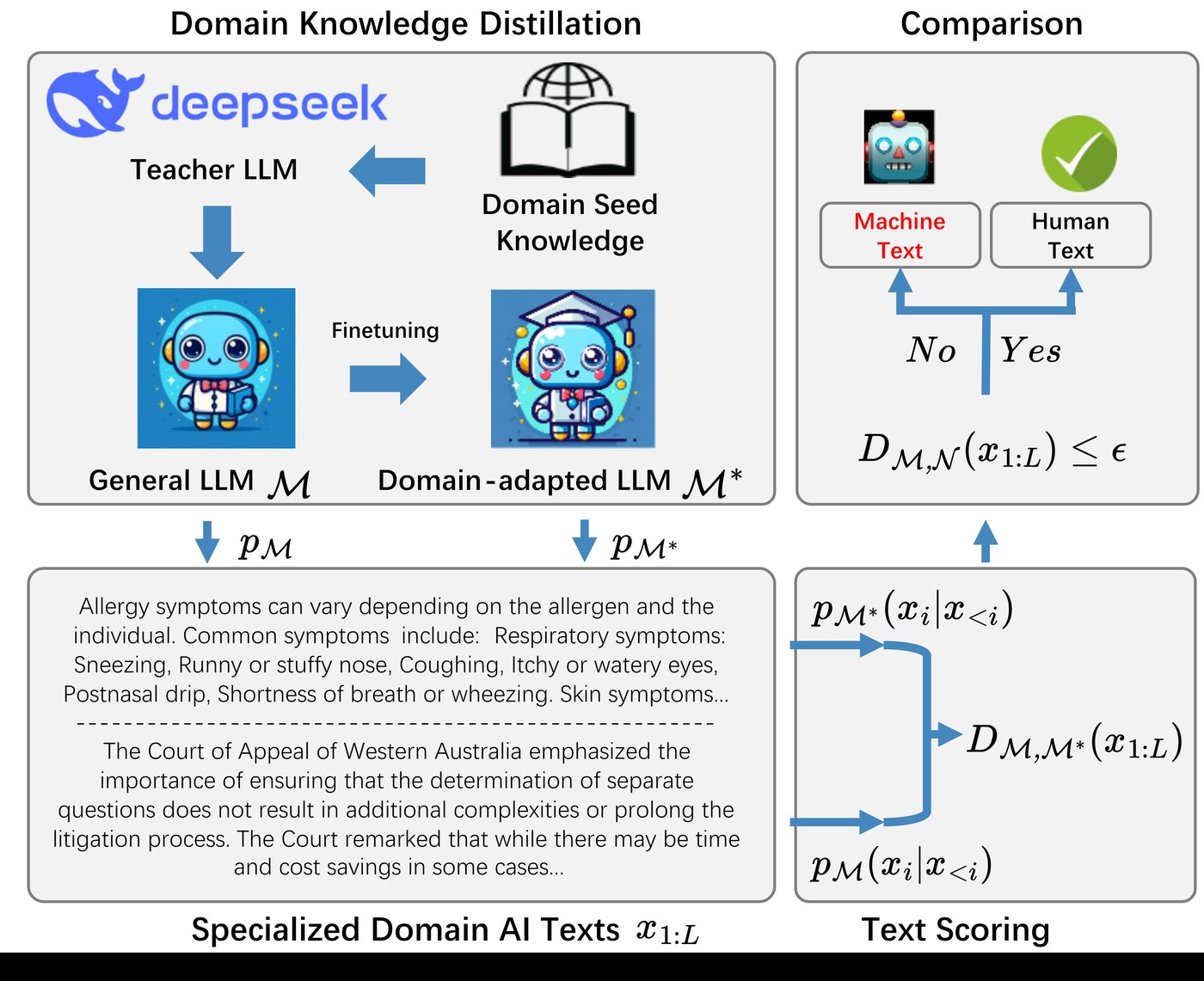
Figure: DivScore framework illustration showing domain knowledge distillation and detection scoring process. 图示:DivScore 框架展示领域知识蒸馏和检测评分流程。
Key Advantages:核心优势:
- Domain Adaptation:领域自适应: Captures domain-specific language patterns through knowledge distillation, making it robust to distribution shift. 通过知识蒸馏捕获领域特定语言模式,对分布偏移具有鲁棒性。
- Zero-Shot Detection:零样本检测: No need for labeled detection training data - works directly on new specialized domains. 无需标注检测训练数据,可直接应用于新的专业领域。
- Theoretical Grounding:理论基础: Based on formal analysis of entropy divergence, providing interpretable detection signals. 基于熵散度的形式化分析,提供可解释的检测信号。
Main Results主要结果
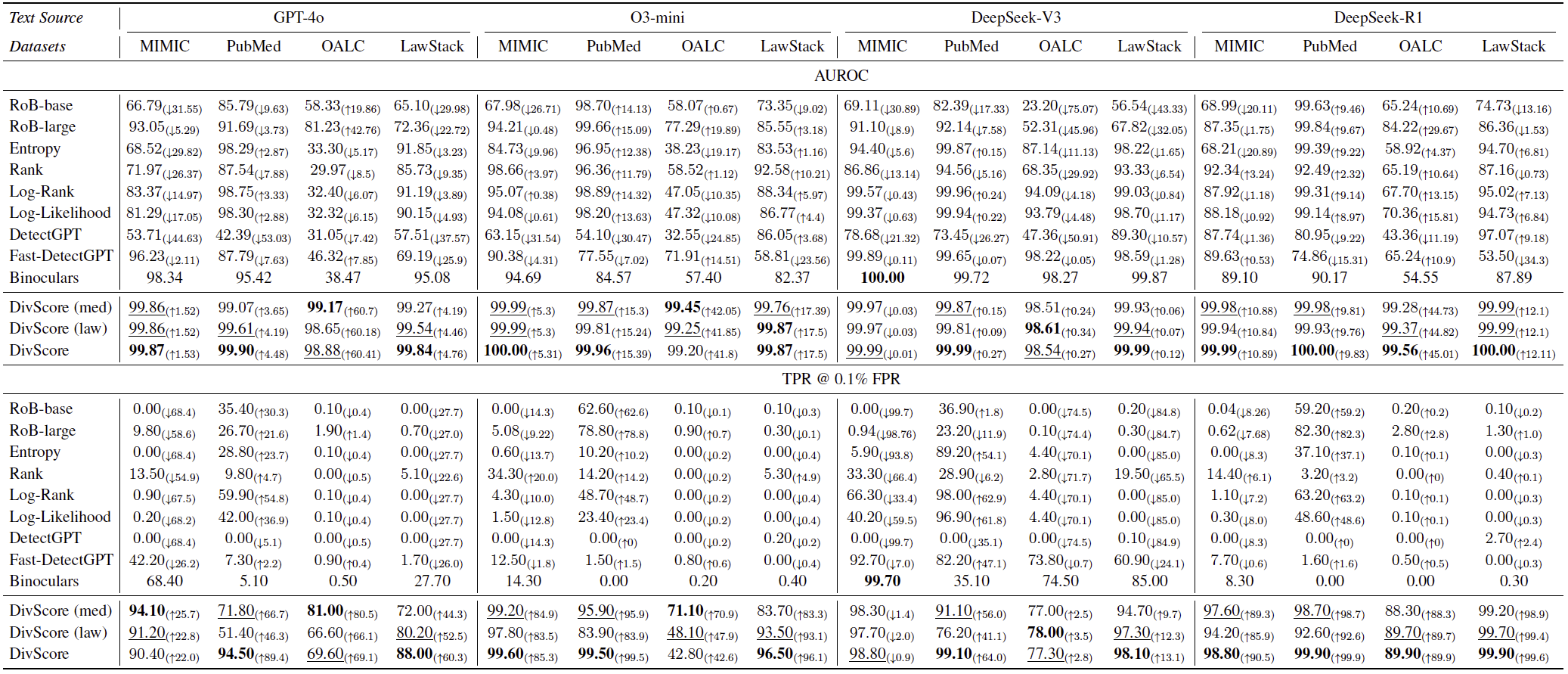
Main results showing DivScore significantly outperforms baselines across multiple specialized domains. 主要结果表明,DivScore 在多个专业领域显著领先基线方法。
Ablation Studies消融实验
AUROC Curves Comparison AUROC 曲线对比
Entropy vs. LogRank Comparison 熵与 LogRank 指标比较
Epoch Ablation Study 训练轮数消融实验
LLM Model Ablation 生成模型消融实验
Impact of Knowledge Distillation 知识蒸馏效果比较
Key Insights关键洞察
- Domain Shift Challenge:领域分布偏移挑战: Existing zero-shot detectors fail on specialized domains due to distribution mismatch between general and domain-specific text. 通用零样本检测器在专业领域因通用文本与领域文本的分布差异而表现不佳。
- Normalized Entropy is Key:归一化熵评分是关键: Comparing entropy between general and domain-adapted models provides robust detection signals across different specialized domains. 比较通用模型与领域化模型的熵,可在不同专业场景提供稳健的检测信号。
- Knowledge Distillation Matters:领域知识蒸馏至关重要: Domain-adapted models significantly improve detection accuracy, with 14.4% higher AUROC compared to baselines. 领域化模型显著提升检测精度,相比基线 AUROC 提升 14.4%。
- Strong Robustness:鲁棒性强: DivScore maintains high performance under adversarial attacks and across different LLM generators, achieving 64.0% higher TPR at 0.1% FPR. 在对抗环境和不同生成模型下,DivScore 仍能在 0.1% FPR 下实现 64.0% 更高的召回率。
Citation引用
If you find our work useful, please cite: 如果这项工作对您有帮助,请引用:
For questions or collaboration, please contact: 如需合作或有疑问,请联系: zhihui.chen@u.nus.edu