Interpretable medical deepfake detection
可解释医学深度伪造检测
MedForge MedForge
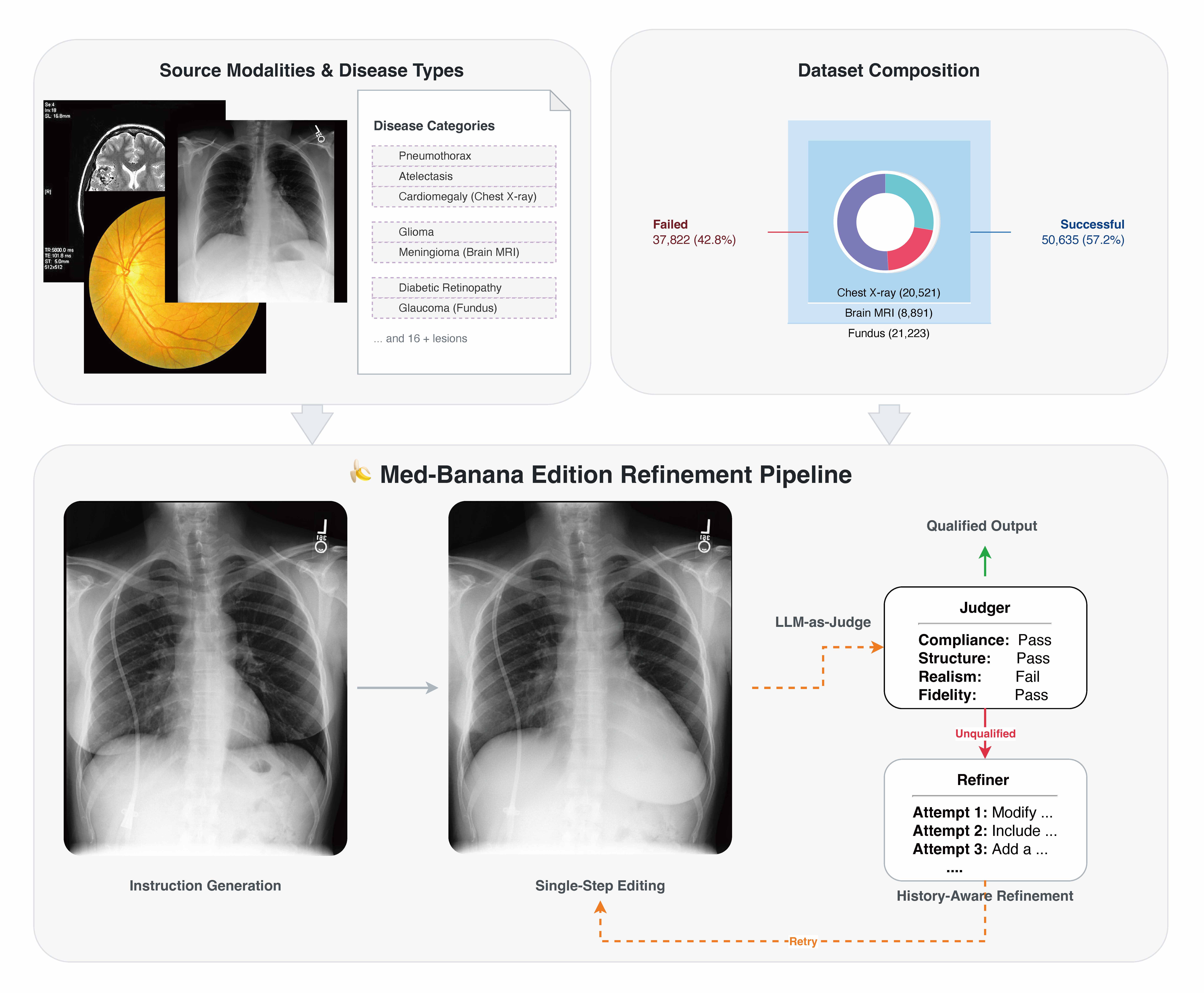
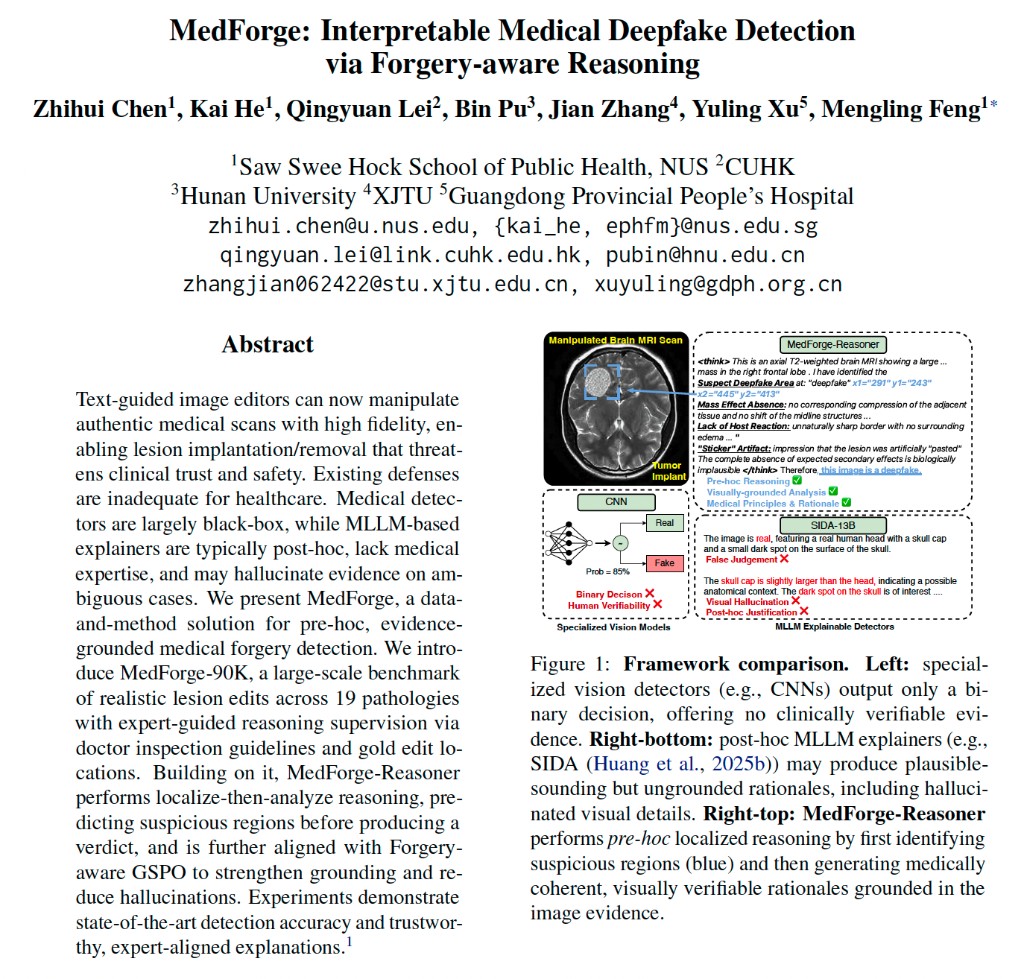
A data-and-model framework that detects medically plausible image forgeries through localized evidence, expert-aligned reasoning, and a Localize-then-Analyze detector. 通过 MedForge-90K 基准、专家对齐推理和先定位再分析检测器,对医学影像伪造进行定位、判别和解释。
ACL 2026 Main
ACL 2026 主会议
19 lesion types
19 类病灶
10 deepfake models
10 种伪造模型